
European Union and Data Sovereignty
The European Union (EU) has gotten very interested of late in the concept of data sovereignty. They’ve realized that almost all the data in the world (92%) is hosted in the United States. As such, they want more of it under their purview.
Statements from German Chancellor Angela Merkle and others in the EU sound very good. So good in fact that they read like something stolen from TARTLE’s own website. They talk about security, competition and ‘fostering trust’. Yet, there is plenty of reason to think that those good words are not genuine and the politicians aren’t necessarily thinking of the best interests of their citizens. Are they even looking at things in the proper light?
As an example, does it really matter where the servers are? It might in the sense of the host country’s government potentially having easy access to them. However, the real power comes from the people generating all the data in the first place. The individuals are the ones who really hold the power of all that data since they are the ones generating it. The servers really are just storage.
What about the big tech companies? Don’t they have the real power in the situation? They are the ones who own the servers and the apps so it makes sense that they have the real power. In a sense, this is true. They can delete and sell data at will in most places, making a ton of money in the process. It’s also a place where the EU lags far behind the rest of the developed world. None of the top twenty tech companies are based in the EU. Perhaps it’s understandable they are feeling slightly inadequate.
Despite the obvious and real power of the tech companies, the true power still lies with the individual. The individual generates all the data. In fact, he decides whether or not he will generate any data at all. That power, however, is largely untapped. That’s because the laws don’t recognize that power for the most part, making it harder for the individuals to understand it as well. So, does the data sovereignty focus by the EU address that issue at all? Will it help people realize the power they really have? Sadly, it doesn’t look that way.
First, they are wanting to force a lot of that server space to their shores. The rule they are wanting to enforce is that any server with data from EU citizens on it has to be located in Europe. What does that accomplish? They get all the access they want for one because they set the rules. They also get taxes, and lots of them, something the EU certainly plans to take advantage of. Recent statements indicate this very clearly, wondering when “cross-border transactions” fall under certain tax regimes. In plain English, this means “when do we get to take people’s money?”
Sadly, all of this means that the EU is really only interested in data sovereignty as it pertains to them. And even then, only as a means of control, to be able access data and tax others for their own purposes. There isn’t anything there about actually empowering the individual.
TARTLE though is doing exactly that. We have set up a system that lets people take control of their digital lives in a way that is easy to do and understand. Our TOS are simple, our website easy to use, and our goals clear. We take no money from the individual sellers that join us. We are in 195 countries around the world so we have no national agenda. All we want to do is help people protect their data so they control when it gets shared and to whom. That shouldn’t be asking too much.
What’s your data worth? Sign up for the TARTLE Marketplace through this link here.
The internet, cloud computing, data and all the rest of it can be amazing when it is used appropriately. Used correctly, these tools can be a massive benefit, helping us to understand the world we live in and to be better able to solve whatever problems come our way. Unfortunately, these tools can be abused all too easily.
It’s like that with all tools. You can use the tool of fire to keep yourself warm, provide light, and cook a meal. An arsonist will take that perfectly neutral tool and use it to burn down a building. A gun can be used to stop a crime or shoot up a school. Digital tools are the same, and just as with those other tools, there is perhaps no more terrifying abuser of digital tools than the government. Just like Nero burning Rome, the KGB using guns and other tools to terrorize their fellow citizens, governments can use the tools of the digital age against their own people.
We’ve talked about this before. China uses the internet to control, rather than foster the flow of information and we recently discussed how New York City uses facial recognition software to profile people. The latest abuse comes out of Morocco where a human rights advocate is currently being held based on falsified charges according to Amnesty International. Apparently, the government does not like Maati Monjib advocating for freedom of expression and is using false data to accuse him of embezzlement. This is frankly terrifying. When the government itself is willing to lie and falsify information to attack its own citizens, there is little any one person can do against that. That’s true no matter where you are or which government is doing the abusing.
What lessons can we take from this situation? One, it is more important than ever to protect your data. There are simply too many bad actors out there who are willing to steal or falsify data for their own ends. Whether the intent is to steal a credit card number and run up the balance or extort a hospital with some ransomware, the need to be careful about privacy is greater than ever. Yet, how does protecting your data from theft prevent anyone from just making stuff up? After all, can’t they just access a given server and insert whatever information they want? Yes and no.
To make that work, the falsified data has to be at least somewhat believable in most cases. Which means they need to have some legitimate data to work with. If your real information is protected, it at least makes that task a lot more difficult. Yet, let’s assume this is possible or that the prosecuting body just doesn’t care. This is why blockchain is important for data. If all data or at least all of your data has a blockchain attached to it, it becomes much harder to falsify. If it doesn’t have the appropriate chain that leads back to you then it isn’t your data. Even if someone figures out how to fake that, it still won’t work because it won’t be duplicated in all the other nodes in the system. A defense, even in a show trial becomes much, much easier.
Of course, a reasonable person will ask how you keep bad actors from using blockchain. Well, you do the best you can. TARTLE screens for known bad actors like actual terrorists. However, there isn’t any way to stop every bad actor before they do something they shouldn’t. Even if you engaged in all the profiling and regulating you can imagine, there would be those who would slip through the cracks, while restricting the freedoms of many more innocents.
TARTLE believes that the free flow of data is paramount. As such we take an innocent until proven guilty approach. Better that ten guilty men go free than one innocent man is punished.
What’s your data worth? Sign up and join the TARTLE Marketplace with this link here.
Lakes are beautiful. If for some reason you don’t live anywhere near one I feel a little sorry for you. Aside from the obvious aesthetics, there is a natural beauty in how they work. On the surface, they may seem to be little more than a hole in the ground full of water. However, dip just below the surface, they are teeming ecosystems with a variety of species and smaller systems coexisting. They also provide abundant raw resources, in the form of fish, nutrient rich sediment, and of course water. One simply need to know how to extract those resources and put them to use. Those aspects form the basis of what is known as the data lake, or the lakehouse method of data management.
In this method, data is stored in its raw, unprocessed form in servers that are designed to be easy to access. Ah, but how useful is that data if it remains in a raw format? Not very, of course. Embedded in the data lake are algorithms that would normally be applied outside of the servers, either before or after storage. In the lakehouse model, the algorithms are there, swimming amongst the data, processing, sorting and moving it to where it needs to go. These ETLs (extraction transfer loads) can be set up to be constantly working, so as data streams into the lake, those algorithms will funnel into your pipeline, giving you a constant feed of freshly processed data. Perhaps best of all, there can be multiple ETLs operating in the data lake at once, making it possible to benefit from multiple analyses of the same or different data simultaneously. The lakehouse method allows all of this to take place with data in real time. Data can be processed and removed from the lake almost as quickly as it streams in.
This is in stark contrast to the older data warehouse method. In this model, data is stored, typically in a processed form in servers for later use. If a business wanted to know something, it would have to go into the servers and find it, with each new problem requiring a new set of software solutions to be engineered. This inevitably leads to stacks upon stacks of servers doing nothing more than storing data that isn’t getting or may never get used. All it does is take up valuable space and resources to simply maintain the servers. What’s more, different kinds of data would often be stored on different servers. Video here, audio there, text on another, and so on. This is just fine if you only need to analyze one kind of data. However, in the increasingly lighting-paced world we live in, that isn’t good enough. Businesses demand the ability to analyze multiple kinds of data at once, integrating them in order to get a better idea of the big picture. The lakehouse method of data storage and analysis allows for quicker and easier results that are more up to date than anything possible via the warehouse.
The lakehouse is also much better suited to our modern cloud computing world. Cloud computing is designed to be fast paced, easily shared, and quickly processed. It also generates data that businesses are interested in tracking faster than ever before. The data warehouse is just too slow and clunky compared to the data lake.
Whoever can best store, process and analyze data in the modern world is best suited to lead whatever field they are in. TARTLE understands this and that’s why we are working to return the power of your own data to you. If you wish, you can add your own data to the lake, working to provide a steady feed of source data, rather than that collected from third parties. This provides better data to the businesses that want to use it and allows you to actively participate in the process and be rewarded for it.
What’s your data worth?
Where is the Life we have lost in living?
Where is the Wisdom we have lost in knowledge?
Where is the Knowledge we have lost in information?
This brief poem from a man who died years before the internet was even a twinkle in DARPA’s eye has surprising relevance to today and the way we treat data. How so? Let’s get into it.
It’s a sad fact that something gets lost in pretty much every transition, whether it be as individuals or as a society. No matter what, a little bit of the baby always seems to get thrown out with the bathwater. Once more experiences were open to more people, a certain appreciation for the simple day-to-day tasks that make life possible got lost. There is natural wisdom in the life of the villager who works from sun up to sun down every day to provide for his family. As we had more knowledge at our disposal it became all too easy to confuse that with wisdom, with learning how to apply that knowledge in a beneficial way. Now, in the present day, we also have a tendency to mistake having a ton of information available with having actual knowledge. We confuse our ability to Google a fact with actually knowing a fact. Well, the fact is, these aren’t the same thing.
That loss and confusion has perhaps never been more prevalent than in the present day in which we are awash in data. Everything is recorded and stored somewhere, from our favorite movie to our last vacation to anything we’ve ever written down. Even our thoughts in a way are being recorded. Because what is data but an expression of our thoughts? Every action we take that is recorded is the result of a thought we had. If our smart refrigerator records that we opened it at two in the morning it is recording our thought that we were hungry. When Amazon records a purchase of Plato’s Republic it shows that someone is thinking about Ancient Greece on some level. If Kay Jeweler’s records a purchase of a gold ring, it’s a record that someone is getting married. All of that data is getting recorded and stored and in some way it reflects our innermost selves. Yet, how do we use all this information? Do we use it to better understand each other and the world we live in? Do we use it to increase our knowledge so we can use it along with our experience to grow in wisdom? Not usually. For the most part, we use it in a far more crass and cynical way. We use it to make a buck.
Now, as we’ve said, there is nothing wrong with making a buck, the problem comes when everything is directed towards that goal, when everything becomes about making more and more money. Even the money made becomes primarily useful in using it to make more money. That’s a little insane if you ask us.
TARTLE believes that people have a greater responsibility with their data than that. We should be using all of this data to grow as people, to be able to help each other, to build a world we can all live in and with. Used in the right way, all of the data we are generating can greatly contribute to some pretty lofty goals. That takes getting back in touch with the people behind the data, remembering that data is not a mere tool to make money but an expression of people’s own selves. That should be treated with respect and used in a way that reflects that. Then maybe we can climb that chain and regain some of the life we’ve lost in living.
What’s your data worth? Sign up and join the TARTLE Marketplace with this link here.
WhatsApp is the biggest message sharing app on the planet. Roughly half the people in India use it, which already accounts for over 450 million customers. While that is a lot, it’s less than a quarter of WhatsApp’s two billion users. As such, anything they do gets a lot of attention, even more since they were bought by Facebook a while back.
This was demonstrated recently when they released some brand new terms of service (ToS) that seemed to go very much against their previous reputation for privacy. One of the major issues in the ToS is the requirement to allow WhatsApp to share your data with Facebook. Also upsetting to many people was the stark either/or ultimatum: accept the terms or you will no longer be able to use the app. Since we value data privacy around the halls of TARTLE we’ve been following the issue closely and have addressed developments in this space a couple of times already.
As you might imagine, WhatsApp has taken a lot of flak for the new ToS and are now in full damage control mode. For one, it looks like the person responsible for the ‘accept our terms or else’ messaging has been fired. Yet, millions of users have switched to other messaging apps. After Elon Musk tweeted an endorsement, Signal downloads went through the rough. Telegram also has seen a surge of 25 million users while other, smaller apps like Viber are publically cutting ties with Facebook.
So what is WhatsApp doing to staunch the bleeding? Other than firing someone for their lousy PR skills, WhatsApp and Facebook representatives are out in force trying to clarify the new ToS. The biggest clarification they are trying to make is that there is no change to messages between friends and family. Those are still completely private. According to them, the only privacy change relates to messages to businesses, which of course is completely optional. That’s great and all, but one does wonder why they didn’t just say that clearly at the beginning. When the backlash first started they just issued ‘no comment’ statements. Why did it take so much time to craft a real statement if everything is fine? At the very least, their messaging is still in poor shape.
Moving on, the official statements also clarify that neither WhatsApp nor Facebook can actually view your private messages. What comes next is more interesting. They say that their plan for messaging integration is still underway, which means that Facebook is still trying to figure out how to bring the WhatsApp people into their bigger monetization strategy. Which, in all honesty likely means the ToS for WhatsApp will be going through another revision or two in the near future. Or it will just get merged with the very profitable Messenger.
For now though, they aren’t listening in or encouraging others to do so, nor are they keeping logs of your contacts or location. Which is very good since most of the cellphone and landline companies do exactly that. This is one of the high points in WhatApp’s recent statements. They rightly consider it a privacy and security risk to keep those kinds of records. Just having them, means you need more servers which is both an expense and a potential path for a hacker. And of course losing control of such records would completely undermine trust in the company.
Going deeper into the statement there are a few cleverly worded statements such as how WhatsApp doesn’t share any group data for ad purposes, which implies that they are sharing data across apps for some purposes. It may also be that they don’t even need to share all that group data to get what they need. One also wonders if this contradicts the above assurances about maintaining the privacy of private messages.
This is why TARTLE is so needed. We don’t play games, we tell why we exist and what our intentions are upfront and in simple language. You sign up with us and we won’t even share your data with ourselves, much less a third party. It goes only where you want when you want it to. That’s it. Your privacy is worth protecting and TARTLE wants to help you do that.
What’s your data worth?
Dogs are man’s best friend. It’s a phrase we are all familiar with. Some have said that dogs are the only animal that has truly been domesticated. Interestingly, this seems to have been the case for a very long time. There is even an 8000-year-old dog buried with its owner and wearing some sort of necklace. Such instances of ancient humans burying dogs exist in many cultures as well, everywhere from Siberia to Turkey. How did this come to pass though? Dogs are not so different from the modern coyote or wolf, both wild animals with no particular affinity for humans. What is it that changed to make dogs evolve in such a different way than their four-legged cousins?
One of the most common theories for how the transition from wild beast to “fetch the paper, boy” is what could be called the ‘slow trust’ theory. The idea is basically that a curious wolf got closer and closer to people at the fire and instead of killing it, some early humans decided to feed it. Over time the wolf became dependent on the human and the human began to teach the wolf. Another is that wolves simply began following humans as they migrated with the seasons, feeding off whatever carcasses the humans left behind from time to time. There is even the orphan theory, the idea that a wolf pup was kicked out of the pack for some reason and was taken in by a hunter. Others eventually copied him and now we have ‘toy dogs’.
Now, researchers are trying to find the genetic source of the modern dog by mapping various canine genomes. Already having done several extensive studies on dog genetics, a team of over fifty researchers led by Dr. Robert Losey at the University of Alberta is directing their microscopes to wolves, specifically those living around 11,000 years ago, the end of the last ice age.
How does this genetic mapping work? It involves looking at the spacing between different genes in the wolves DNA. Should these genes be common among wolves in a given area (not just a unique mutation) and then is found to be shared by dogs in say, Turkey, there is clear evidence of a genetic link. What Dr. Losey and his team are doing that is new is also mapping the genes of the humans buried near them. So if there are genetic traits shared by people in Siberia who are buried with or near wolves or wolf-like dogs and farmers down in Turkey who are buried near their dogs it would indicate it wasn’t just wolves who adapted to humans and became dogs along the way. It would suggest that humans also developed, alongside their canine companions, or at least that it was a certain type of human that was more likely to form a bond with wolves and dogs.
Part of the drive for this new avenue of research is that no one seems to be able to come up with a convincing answer to how wolves became domesticated dogs. Every now and then a theory gains traction but only for a year or two before new data comes out and sends them back to the drawing board. What he is trying to do is get back to the source, the origin of that transition. This is the obvious thing to do, to try to get data from the source whenever possible. That way, you get the best, most honest data on any subject, whether it’s mapping canine genetics or crime scene investigation. Even your grandmother probably told you to get your information “straight from the horse’s mouth”.
We know instinctively that we should always learn from the source, to start from the beginning. That’s exactly what TARTLE is doing with data, getting companies to go to you, the source of the data rather than a bunch of opportunistic third parties. That way, they can learn, adjust, and refine their own models based not on guess work, assumptions, and agendas but on data gained from real people eager to make a difference.
What’s your data worth? Sign up and join the TARTLE Marketplace with this link here.
Everything is moving to the cloud. We hear this all the time. Especially since more people than ever are currently working from home and ordering things online thanks to the various responses to COVID. All of that online activity has been generating piles and piles of data, so much so that data storage companies have had to scramble to deal with it. Thus, new data centers, located in massive but otherwise innocuous buildings full of server stacks are springing up.
There are a lot of interesting and counterintuitive aspects to this trend. One is that our increasingly digital lives are causing a small boom in brick and mortar construction. Because of the obvious need for extensive electrical and HVAC capabilities these data centers can’t be easily installed in a refurbished warehouse or old office building. They often need a brand new building to be able to handle all the unique demands of a modern data center. This creates construction jobs and a few others in security and IT to keep the servers working.
Another unusual aspect to consider is the fact that the cloud isn’t really a cloud. Sure, when you upload a document to the cloud, it is easy to share with others and access from anywhere with an internet connection. However, that document is still stored in a specific physical location. In a way, the cloud as it currently exists is actually more centralized than ever. Stay with me on this. Before everything was getting put on the cloud, your information was typically kept just in your hard drive and the drive of anyone you shared it with. That is pretty siloed and keeps it out of the hands of people who might benefit from access to it. Yet, data as a whole was more spread out, over several different drives in multiple buildings, each possibly with its own servers.
This made it more difficult to share but also to hack the data. A single accident like a power surge was unlikely to wipe out vast swaths of data. Now, with the cloud and increasing amounts of data stored in these massive server farms it is in faact easier to hack, or be lost due to happenstance. How should we deal with this situation? What alternatives are there since it is unlikely we’ll be going back to the old model. After all, the cloud model has provided numerous advantages in cost savings and data sharing efficiency. For now at least, it seems we need those massive centers full of server stacks. Yet, this is merely a temporary fix, a band aid.
The question then remains, what is a better solution for this situation? The answer lies in the continued drive to decentralization. If cloud computing arose from a need to decentralize work, the solution to how to best handle all that data should lie in the same direction. While the details still need to be worked out, solutions that make use of blockchain technology are the most likely. These would make use of this cryptocurrency technology to harness the storage and computing power of devices large and small across the planet. Imagine if millions worldwide signed up to a system that would dedicate a portion of the storage and computing capacity of their smartphones and laptops to cloud computing. Each one functions as a node in a massive network.
These kinds of systems already exist. The oldest of note is SETI which began allowing people to hook up their computers to the SETI data network over a decade ago. These computers process data from SETI during what would otherwise be downtime, allowing that data to be processed much more quickly and efficiently than if it was just waiting for time at centralized supercomputers. The same method has been used in other capacities such as decoding genomes. So, why not apply the same principle to cloud computing generally?
This is exactly in line with TARTLE’s vision. We’re trying to help build a world in which data is not controlled by the few but by the many, by the people who create it in the first place. It’s just one part in the decentralization movement, a movement that aims to put people back in control of their own data and lives.
What’s your data worth? Sign up and join the TARTLE Marketplace with this link here.
TARTLE may be a young company but it already stretches around the world with users in many countries. One of the many countries you can find us in is the Philippines. So it’s time we gave a little shout out to the amazing people of that small nation and their culture.
If you aren’t familiar with this little country, it’s a collection of islands in the Pacific, far off the eastern coast of Asia. It was ravaged by WWII and is covered in jungle with a volcano or two thrown in just to make things exciting.
The culture there is an interesting one. On one hand, there are tent and shanty cities built right next to railroad tracks. On the other, everyone there has a smartphone and is constantly sending texts or scrolling Facebook. It’s a deeply religious and developing culture with one foot in the past and the other in the future. As such, it’s kept many of its older qualities like a strong and cheerful work ethic and generosity while showing a significant aptitude for learning new technologies to keep them connected across the islands and with friends and family who move to the USA.
One of those people who made the journey across the deep blue sea is married to one of the people who work for us here at TARTLE. Alex (our co-founder for those just tuning in) went over there for dinner and was talking with everyone when he realized the wife was missing. Well, it turns out she was in the kitchen working on dinner, even after working all day. When it was time to eat, a veritable feast was laid out with mountains upon mountains of food. And yes, this is normal for them. It’s one of the admirable things about Filipino culture, the work never stops. Men and women are both constantly in motion, accomplishing something that needs to be done, yet few ever complain about it. That’s because they do it all out of a sense of service, a desire to care for others that leads them to really put themselves into their work.
It’s exactly these kinds of people that TARTLE is striving to bring into the fold. Anyone who puts that kind of spirit and effort into just normal, daily life deserves to be rewarded for it. That’s true of their data use as well. When they are spending time on their phones, checking out the news, shopping or keeping up with people via Facebook, they are just generating profit for that company. The people of the Philippines deserve a little something back for that. After all, when you’re working on getting out of the tent by the railroad tracks and into something a little nicer, every little bit counts. By working through us, they have the chance to take that data they are generating and turn into a good subsidy for their lives and use it however they want. Though if Alex’s recent dinner is any indication, it just might go into helping make another mountain of food, which is no bad thing either.
TARTLE welcomes everyone, wherever you are from to sign up with us. We want to help you, whether you are driving a cab in Moscow, roaming the desert in Libya, working in a cubicle in Des Moines, Iowa, or running a fishing boat in the Philippines to take control of your data. Whether you just want to be able to generate some extra income by selling your data or share your data to specifically help causes you care about, TARTLE is there to make it all possible.
What’s your data worth? Sign up and join the TARTLE Marketplace with this link here.
Data, it’s kind of a big topic here at TARTLE HQ. It’s the main thing we talk about and work with every day. That’s because we recognize two important things: one, that organizations of all kinds are making ever more conscious use of the available data in their decision making and two, that there is more and more data available.
As these organizations have come to realize the importance of their operations they’ve begun finding more ways to gather it faster and store more of it. This has given rise to fiber optic lines getting run through the mountains or under the oceans in an effort to gather data faster. In some applications such as the stock exchange, trading firms even take distance to the main servers into account when building a server hub. Things happen so fast that fractions of a fraction of a second matter. This also has of course given rise to massive server stacks around the country so all of this data can be stored for later analysis.
Those stacks and stacks full of data have spawned a whole new field known as data science. In theory, the whole point of data science is to sift all of that collected and stored data in order to get usable information out of it. Naturally, there is a whole process to that. Yet, is the whole process really necessary? Or more accurately, how helpful is it? First, let’s take a quick look at it.
The first step is to identify an issue and come up with a hypothesis as to the underlying problems. The next step would be to gather the data necessary to test the hypothesis followed by refining the data into an easily digestible form. This in turn is followed by identifying and refining the appropriate algorithms that will then be set the task of finally identifying solutions.
So, does this process make any sense? If we were only analyzing new animal migration patterns or the behavior of oxygen at a particular temperature, it would be perfectly appropriate. That basic process (with some modifications to make it fit the actual scientific method) would be perfectly fine for dealing with the material world. Even when dealing with people it might be okay if you were content with generalizing large groups. Yet, how many people like being just lumped in as one number in a group? We’re pretty sure no one likes getting generalized. Not to mention, why be content with a generalization? Surely we can do better?
Fortunately, we can do better. TARTLE exists because we can and should do better. What if we told you that there is a way to cut through the guesswork, to cut through the hypotheses and the refining of the algorithms and visuals and get straight to the heart of the matter? What if you didn’t have to guess and generalize? Good news! All of this is possible precisely because we are dealing with people. Why does that matter? What is different about people? What can you do with them that you can’t do with birds or oxygen atoms? You can go straight to them and ask a question. Even better, those people can answer you.
How does this work in real life? Simple. You suspect there is a particular issue your organization can help with. Since you know the issue, you know the demographic you need to talk to. Since you are already part of TARTLE, you identify the group that fits what you need and ask them a series of relevant questions and they give answers. You take those answers which might confirm your issue or point to another one altogether and since you were smart enough to also ask about suggested solutions, you take those suggestions and see if those answers point to things your organization can in fact deal with. If the answer is yes, you roll out a proposed solution to the same group of people who either affirm the solution or suggest refinements.
If you notice, the process is actually similar. However, with TARTLE, the guesswork stops almost immediately because you are going directly to and working with people instead of operating on hunches. You get to go right to the source to get the best data possible so you can come up with the best solution possible.
What’s your data worth?
Few topics in the modern day are more contentious than that of climate change. Well, let’s face it, almost every topic is contentious today but climate stability has been the subject of much debate for decades and that doesn’t look to be changing anytime soon.
This fact has just recently been demonstrated yet again by a recent study released by Bjorn Lomborg that looks at the effects of climate change. One part in particular is interesting, which would be the graph.
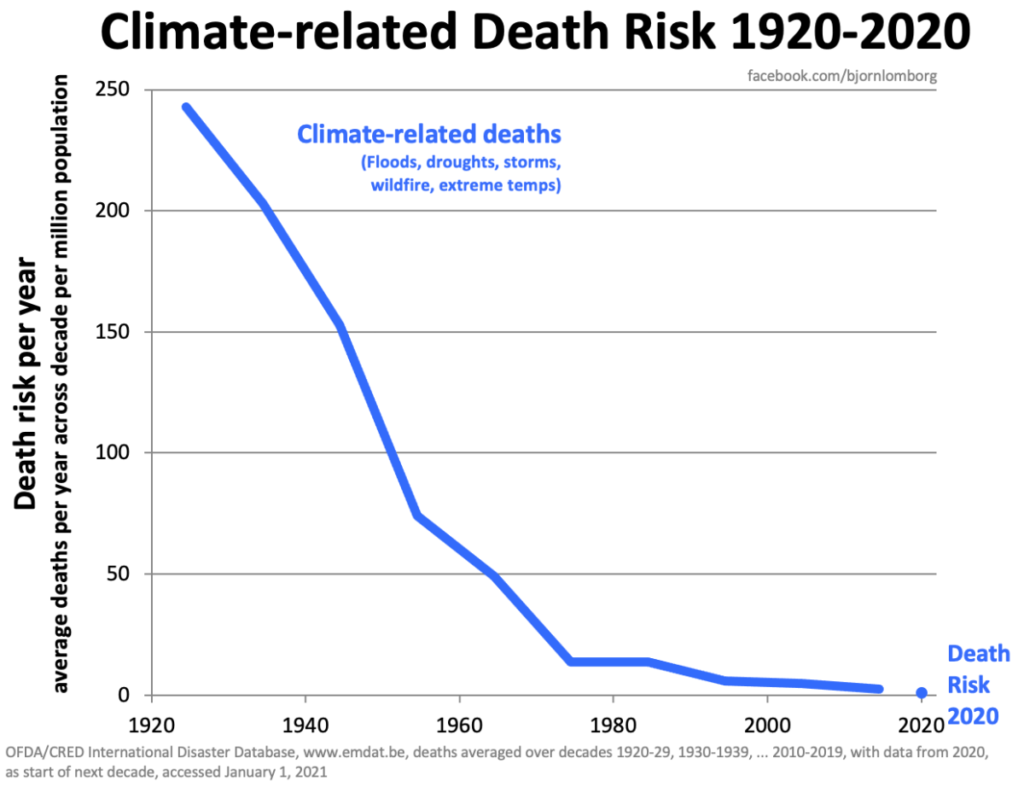
The graph in question shows the number of deaths related to climate plotted out from 1920 to 2020. Climate-related deaths here means anything involving flood, droughts, wildfires, extreme hot or cold temperatures, and storms.
This graph has garnered a great deal of attention because it shows the deaths going from around 250 per million per year in 1920 to virtually none today. Many people are looking at this graph and deciding that climate change isn’t anything to be concerned about.
On the face of it, this isn’t a totally unreasonable conclusion. However, there are a couple of important points to emphasize. The first and most significant is that no one should be reaching conclusions about anything based on one graph, or on any other single point of data for that matter. The second point is related, one graph, while reflecting something true doesn’t necessarily take any number of other data points into consideration.
What do we mean? First, for the sake of argument, we’ll take the numbers presented for granted, that the numbers of climate-related deaths for each year are what the graph says they are. After all, the article is only a few pages and there isn’t time or space here to dig deep into the methodology. Second, we should stop and consider some reasons that climate-related deaths might have gone down other than climate change not being a thing. After all, even if we don’t take other factors into consideration, the graph doesn’t really argue against the idea of climate change. Rather, it would seem to argue that climate has gotten better, which virtually no one believes.
What are some of these other factors we should consider? These are mostly centered on the fact we have made a lot of material advances in the last hundred years. Our medical treatments have improved by leaps and bounds since 1920, dramatically improving life expectancies. We live longer and healthier so what once might have been major changes in air quality or temperature swings can be managed by individuals much better than before.
Housing for vast numbers of people has improved as well. While once, a major thunderstorm could have destroyed rudimentary shacks out on the prairie killing everyone inside, now there are sturdy homes with concrete basements that can handle anything short of a tornado.
Disaster response has also gotten much better. While today, helicopters deliver pallets of sandbags to flood zones practically on demand or patrol areas looking for people to rescue, or airplanes dump tons of water scooped out of a local lake onto a wildfire, such technology didn’t even exist outside of a notebook in 1920.
Related to that is the fact there have been major migrations to the cities which by their nature are less susceptible to climate-related issues. A big contributor is the rise in quality and affordable heating and cooling. In 1920, the relief from a blistering hot summer was a breeze or a cool stream, not turning up the AC. It’s the same with heating. How many people froze to death in 1920 while it is practically unheard of today?
None of these things seem to be considered in this graph of death rates, yet factors like this are necessary to get the whole picture. That’s why TARTLE is such a proponent of getting accurate data from as many direct sources as possible. When you are dealing with large samples of high quality source data, you get a better and less skewed view of the whole picture.
What’s your data worth? Sign up and join the TARTLE Marketplace with this link here.

